
How Captur Compressed a Multi-Task Model into the Size of a Single Photo
Shrinking model size on mobile, without sacrificing performance
Every millisecond matters in operations. Whether it’s verifying a delivery, detecting a road hazard, or validating a rider’s compliance, latency and reliability directly impact safety and customer experience. But until recently, running advanced AI models on mobile devices meant a painful trade-off: shrink the model and lose accuracy, or keep performance and sacrifice speed and memory.
At Captur, we decided that compromise wasn’t good enough. The result? A multi-task model compressed to under 10MB (about the size of a single photo on your phone) running at real-time latency across iOS and Android. And the kicker: it didn’t just maintain performance, it boosted it.
Compression to <10mb
Historically, production-ready models for logistics tasks weighed in at 10–20MB per task. Multiply that by hazard detection, rider compliance, and vehicle localization, and suddenly your “mobile-ready” bundle balloons to tens of MB—crippling both load time and device performance.
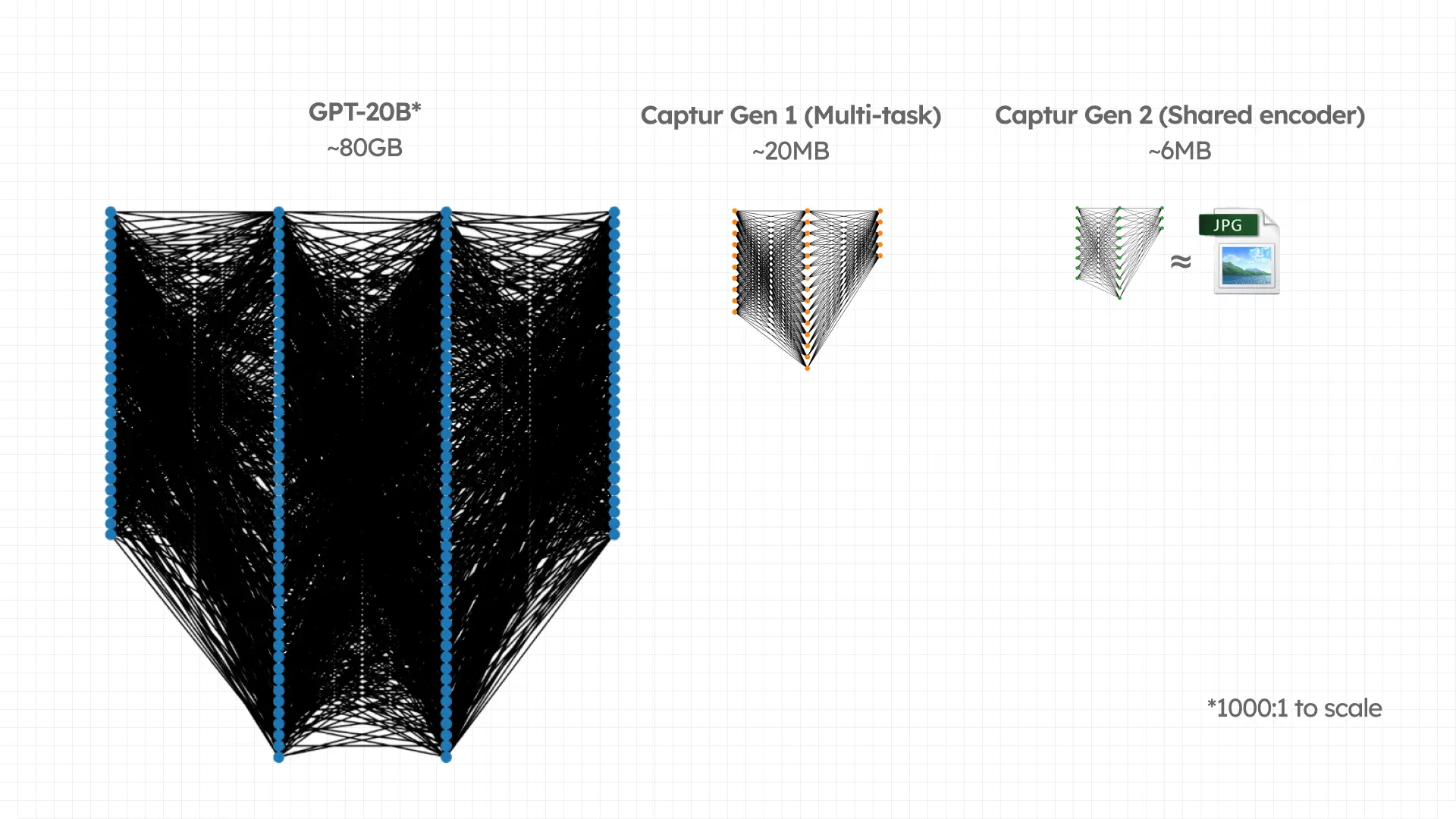
Captur’s shared encoder architecture changed the equation. By distilling knowledge from multiple specialized models into a single compact one, we cut model size by 71%, from ~20MB per bundle down to just 6MB.
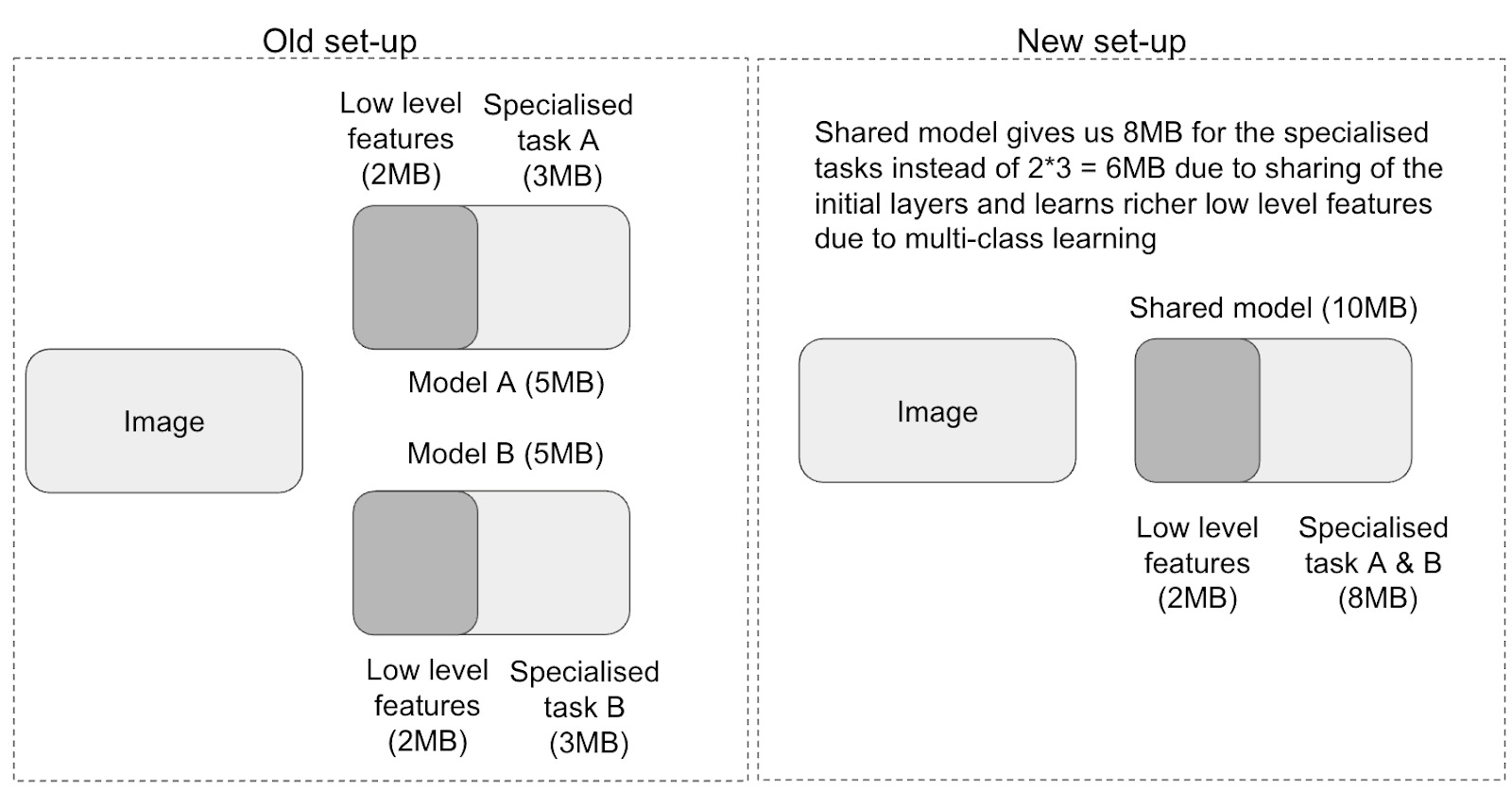
That’s smaller than the average photo in your camera roll, and yet, without pruning away critical performance.
Without Degrading Performance → Surprise Boost
The expectation was clear: smaller model, worse performance. But that’s not what happened.
Instead, by combining knowledge from multiple “teacher” models, our shared encoder student model learned better representations. For example:
A hazard-only model (200MB) achieved a PR AUC of 84.65.
Our multi-task distilled model (<10MB) reached 93.38 PR AUC on the same task.
In other words, while shrinking the model significantly, performance actually increased by 5–8%. Latency also improved—one inference now runs in about a third of the time, delivering real-time 30FPS performance.
This counterintuitive result came from cross-task learning. Data from task A reinforced performance on task B. Compliance checks improved with context from other tasks. Instead of siloed models duplicating effort, we now had one model learning more efficiently from everything at once and using all the data Captur had.
Across All Devices
Compressing a model is one thing. Running it consistently across the fragmented world of mobile hardware is another.
On iOS, Core ML seamlessly schedules models across Apple’s neural accelerators. On Android, the story is trickier: devices vary from flagship phones with custom NPUs to budget devices relying on OpenGL. Historically, this meant a larger variance in performance observed on Android.
Captur closed that gap. By optimizing the architecture and carefully testing across different hardware, we achieved near parity. Today, whether you’re on the latest iPhone or a three-year-old Android, the shared encoder model runs smoothly at ~30FPS.
The Next Frontier?
Captur’s shared encoder architecture delivers a model that’s:
3× faster (real-time on both iOS & Android)
71% smaller (<10MB)
5–8% more accurate (thanks to multi-task learning)
What started as an effort to reduce memory footprint ended with a breakthrough: smaller can mean better. For fleet operators, delivery platforms, and mobility companies, this means deploying advanced compliance and safety AI anywhere—without worrying about device limitations.
The next frontier? Adding new tasks without bloating the model, while keeping the same lightning-fast, cross-device performance. But for now, we’ve proven that a photo-sized AI can transform how logistics runs in the real world.